Workload Identityを利用してGoogleドライブのファイルをS3へコピーする
今回は Google ドライブのファイルを AWS にコピーする方法を紹介します。
経路は、AWS の lambda をトリガーにして AWS の IAM ロールから、GPC の Workload Identity を利用して Google ドライブにアクセスする方法です。Workload Identity を利用するメリットは GPC 側に AWS の認証情報を渡さずに済むので、実装コストもセキュリティ面も良さそうです。
前提
- AWS のアカウントを持っている
- GCP のアカウントを持っている。
gcloudコマンドが利用できる状態になっている
ちなみに皆さんマルチクラウドでの開発になれていますでしょうか?
私はこれまで関わってきたサービスとか、まぁ一応マルチクラウドではあるのですが、私の知識は AWS に偏ってます。つまりは GCP の知識はほぼ皆無です。なので GPC 側の説明はかなり省略で「こうやったら動いた」程度の話になります 🙇♂
GCP 側の準備
さて、GCP の IaC は何を使うのが正解なのかよくわからないのでシンプルに shell スクリプトで作成しました。
こんな感じになりました。
#!/bin/sh
SUFFIX=20240320
PROJECT_ID=pj-test-$SUFFIX
ACCOUNT_ID=test-account-$SUFFIX
POOL_ID=test-pool-$SUFFIX
PROVIDER_ID=test-provider-$SUFFIX
AWS_ACCOUNT_ID=123456789000 # 任意のAWSアカウントID
AWS_ROLE=arn:aws:sts::$AWS_ACCOUNT_ID:assumed-role/hoge
# Projectを新規で作成する
gcloud projects create $PROJECT_ID
gcloud config set project $PROJECT_ID
# サービスアカウントを追加
gcloud iam service-accounts create $ACCOUNT_ID --display-name=test_account
# Workload Identity APIを有効化する
gcloud services enable iamcredentials.googleapis.com
# Workload Identity Poolを作成
gcloud iam workload-identity-pools create $POOL_ID \
--location="global" \
--display-name=test_pool
# Workload Identity poolにプロバイダを作成
gcloud iam workload-identity-pools providers create-aws $PROVIDER_ID \
--location="global" \
--workload-identity-pool=$POOL_ID \
--account-id=$AWS_ACCOUNT_ID \
--attribute-mapping="google.subject=assertion.arn,attribute.aws_role=assertion.arn.contains('assumed-role') ? assertion.arn.extract('{account_arn}assumed-role/') + 'assumed-role/' + assertion.arn.extract('assumed-role/{role_name}/') : assertion.arn"
# サービス アカウントにアクセス権追加
PROJECT_NUMBER=$(gcloud projects describe $(gcloud config get-value core/project) --format=value\(projectNumber\))
SERVICE_ACCOUNT_EMAIL=$(gcloud iam service-accounts list --filter='display_name=test_account' --format='value(email)')
gcloud iam service-accounts add-iam-policy-binding $SERVICE_ACCOUNT_EMAIL \
--role=roles/iam.workloadIdentityUser \
--member="principalSet://iam.googleapis.com/projects/$PROJECT_NUMBER/locations/global/workloadIdentityPools/$POOL_ID/attribute.aws_role/$AWS_ROLE"
# 構成情報の取得
gcloud iam workload-identity-pools create-cred-config \
projects/$PROJECT_NUMBER/locations/global/workloadIdentityPools/$POOL_ID/providers/$PROVIDER_ID \
--service-account=$SERVICE_ACCOUNT_EMAIL \
--aws \
--output-file=google_config.json
echo email:$SERVICE_ACCOUNT_EMAIL
echo project_number:$PROJECT_NUMBER
やっていることはコメントに書いてある通りです。
SUFFIXは GCP は名前空間でぶつかることが多い気がするので、名前空間を変えるために作ってます。値はなんでも良いので、もし名前が衝突するようなら変えてください。
AWS_ACCOUNT_IDは GCP へアクセスする AWS アカウントの ID を入れてください。
基本的に公式の資料を読みながら、コマンドを整理してるだけなので、もし細かく知りたいとかありましたら公式読んでいただければと思います。
あとはこれを ↓ な感じで実行してください。
$ sh gcp_setup.sh
そうするともれなくエラーがでます。Workload Identity の API を有効化する API を叩いているのですが、なぜかそのあとでエラーになってしまいます。これの回避方法がわからず、とりあえずもう一度叩くと2回めはうまくいくので、もう一度叩いてください。(気持ち悪さしかないですが)
$ sh gcp_setup.sh
成功すると、google_config.jsonが生成されます。これを後で使います。
またemailとproject_numberがコンソールに出力されます。
API は有効化しないと利用できないので、↓ の{project_number}のところの値を書き換えてブラウザでアクセスし、API を有効化してください。
次に Google ドライブにアクセスしたいディレクトリをブラウザで開きます。
サンプルでは「99_dev-test」というディレクトリを利用します。
このディレクトリの共有設定を開いて、先のemailをコピーして登録します。

次にこのディレクトリの ID を取得します。
ディレクトリを開いているときの URL が ↓ な感じですが、
https://drive.google.com/drive/folders/xxxxxxxxxxxxx_xxxxxxxxxxxxxxxxxxx
xxxxxxxxxxxxx_xxxxxxxxxxxxxxxxxxxの部分が ID です。
最後にこのディレクトリに適当にファイルををアップロードしておきます。
ここでは ↓ のファイルをアップロードしました。
dummy
これで GPC 側は準備完了です。
AWS 側の実装
今回作るものはこういったものになります。
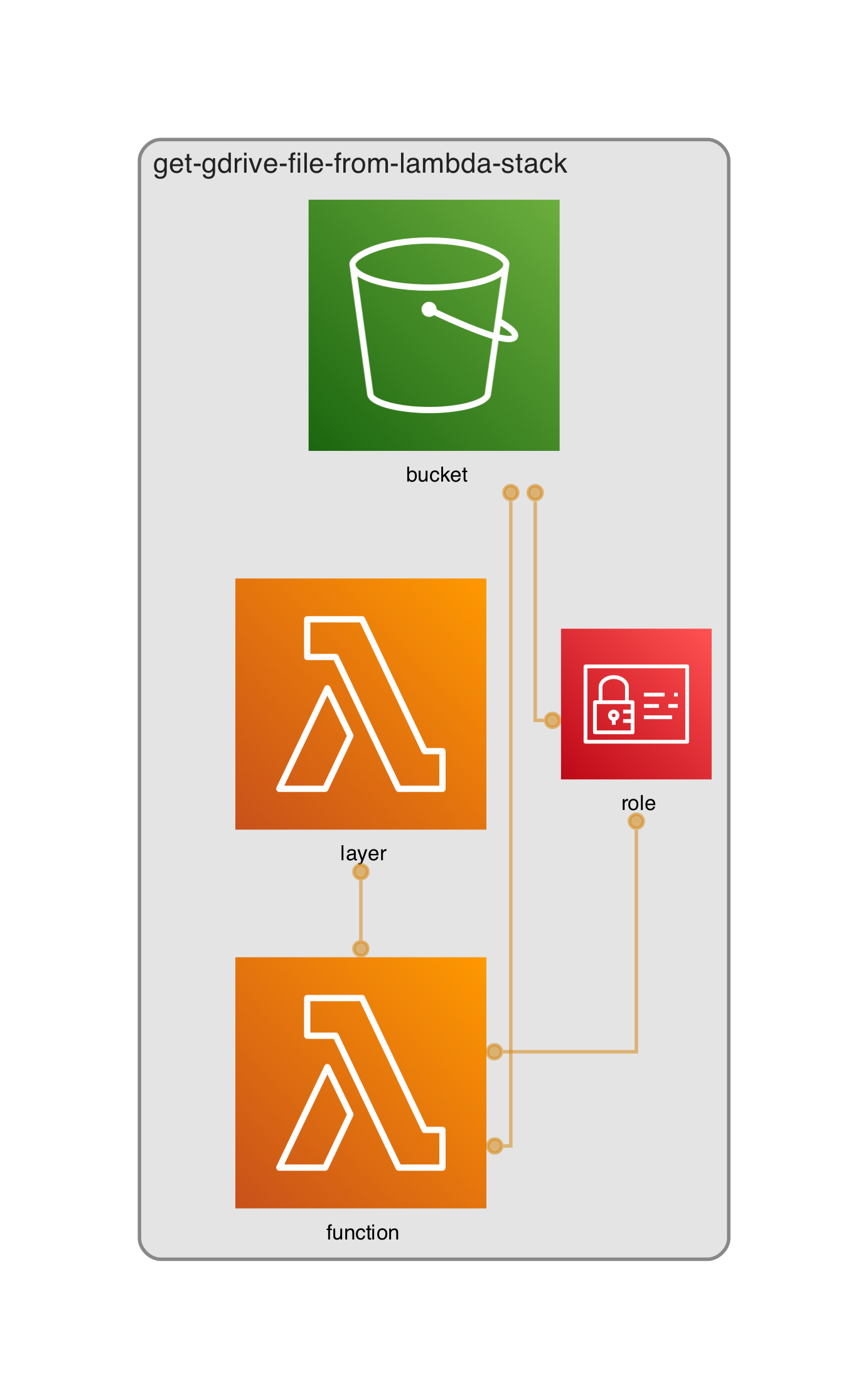
lambda を手動で動かしてあげると、Google ドライブのディレクトリ内のファイルが S3 へコピーされます。
Layer を使っている理由は、lambda コンソールでのトライアンドエラーを少しでも楽にするためです(汗)
ということで CDK のテンプレートはこんな感じ。GOOGLE_DRIVE_FOLDER_IDには先程コピーした Google ドライブのディレクトリの ID を入れてください。
import pathlib
import aws_cdk as cdk
from aws_cdk import BundlingOptions, aws_iam, aws_lambda, aws_s3
GOOGLE_DRIVE_FOLDER_ID = "xxxxxxxxxxxxx_xxxxxxxxxxxxxxxxxxx"
app = cdk.App()
stack = cdk.Stack(app, "get-gdrive-file-from-lambda-stack")
bucket = aws_s3.Bucket(
stack,
"bucket",
block_public_access=aws_s3.BlockPublicAccess.BLOCK_ALL,
removal_policy=cdk.RemovalPolicy.DESTROY,
auto_delete_objects=True,
)
layer = aws_lambda.LayerVersion(
stack,
"layer",
code=aws_lambda.Code.from_asset(
str(pathlib.Path(__file__).resolve().parent.joinpath("runtime/layer")),
bundling=BundlingOptions(
image=aws_lambda.Runtime.PYTHON_3_12.bundling_image,
user="root",
command=[
"bash",
"-c",
"&&".join(
[
"cp -aur . /asset-output",
"cd /asset-output/python",
"pip install -r requirements.txt -t .",
]
),
],
),
),
compatible_runtimes=[aws_lambda.Runtime.PYTHON_3_12],
)
# IAM role for Lambda
role = aws_iam.Role(
stack,
"role",
role_name="hoge", # CDKデフォルトのロール名だとGoogle側のAPIの文字数制限に引っかかるので物理名を強制。
assumed_by=aws_iam.ServicePrincipal("lambda.amazonaws.com"),
managed_policies=[aws_iam.ManagedPolicy.from_aws_managed_policy_name("service-role/AWSLambdaBasicExecutionRole")],
)
bucket.grant_write(role)
aws_lambda.Function(
stack,
"function",
code=aws_lambda.Code.from_asset(
str(pathlib.Path(__file__).resolve().parent.joinpath("runtime/app")),
),
runtime=aws_lambda.Runtime.PYTHON_3_12,
architecture=aws_lambda.Architecture.ARM_64,
handler="index.handler",
role=role,
layers=[layer],
timeout=cdk.Duration.seconds(30),
environment={
"BUCKET_NAME": bucket.bucket_name,
"FOLDER_ID": GOOGLE_DRIVE_FOLDER_ID,
},
)
app.synth()
長いですが特別なことはせず、S3 に書き込み権限のある lambda を作成しただけです。
Layer は ↓ のようなパスにファイルが1つ入っているだけです。
boto3==1.34.65
google-api-python-client==2.122.0
Layer の詳細は過去の記事を参照していたただければと思います。
lambda のハンドラーは以下になります。
import io
import json
import os
import boto3
from google.auth import aws
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from googleapiclient.http import MediaIoBaseDownload
FOLDER_ID = os.getenv("FOLDER_ID")
BUCKET_NAME = os.getenv("BUCKET_NAME")
bucket = boto3.resource("s3").Bucket(BUCKET_NAME)
def get_drive():
with open("./google_config.json") as f:
json_config_info = json.loads(f.read())
credentials = aws.Credentials.from_info(json_config_info)
return build("drive", "v3", credentials=credentials)
def download_file(drive, file_id):
try:
request = drive.files().get_media(fileId=file_id)
file = io.BytesIO()
downloader = MediaIoBaseDownload(file, request)
done = False
while done is False:
_, done = downloader.next_chunk()
except HttpError as error:
print(f"An error occurred: {error}")
file = None
return file.getvalue()
def upload_file_to_s3(file_name, file):
bucket.put_object(Key=file_name, Body=file)
def process_files(drive):
# https://developers.google.com/drive/api/guides/search-files?hl=ja
query = " and ".join(
[
f"'{FOLDER_ID}' in parents",
"mimeType='text/plain'",
]
)
results = drive.files().list(q=query).execute()
items = results.get("files", [])
for item in items:
file_name = item["name"]
file_id = item["id"]
file = download_file(drive, file_id)
upload_file_to_s3(file_name, file)
def handler(event, context):
drive = get_drive()
process_files(drive)
ここはboto3とgoogleapiclientの使い方の話なので「こんなコードでコピーできます」くらいにとどめます。
最後に GPC 側の準備で生成されたgoogle_config.jsonをruntime/appにコピーしてください。
そしてデプロイします。
$ cdk -a "python app.py" deploy
動作確認
lambda のコンソールで手動で実行して、ファイルがコピーされることを確認します。
lambda をコンソールから手動実行すると ↓ な感じで Google ドライブのファイルが S3 にコピーされました。
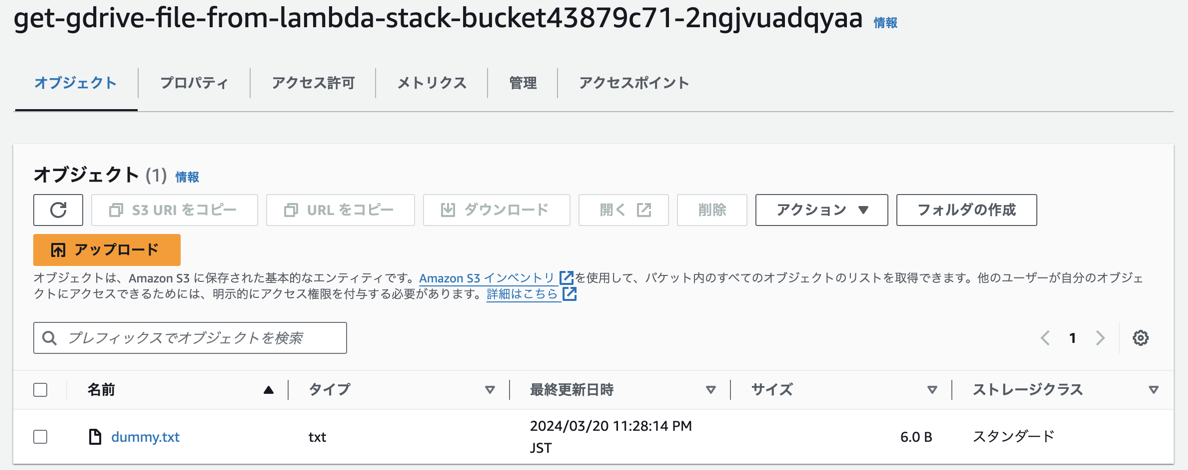
念の為中身も確認してみます。S3 から Download してきて cat をたたきます。
$ cat dummy.txt
dummy
良さそう。
最後に
今回は AWS から GPC の Google ドライブへアクセスして、ファイルを S3 へコピーする方法を紹介しました。
GCP、AWS 側でそれぞれリソースを作成しているので「結構たいへんだなー」という気持ちはありますが、仮に「GAS で Google ドライブから AWS へデータをアップロードするんだ!!」とか比べるとだいぶ良い気がします。
また今回のディレクトリのコピーですが、ファイルだけのコピーでディレクトリはコピーできなかったり、ファイル数にも上限があったりします。なので実際に利用しようと思った場合はもう少しいろいろ追加してあげる必要があるので注意してください。
以上です。最後までお付き合いくださりありがとうございました。
今回のリポジトリはこちら
https://github.com/sisi100/get-gdrive-file-from-lambda
感謝!
記事の表紙は bess.hamiti@gmail.com の Pixabay の画像を使わせて頂いております。ありがとうございます!